Python
 comments powered by Disqus
comments powered by Disqus
stable-diffusionを試してみました
テキストから画像を生成する
AIネタ続きます。テキストから画像生成できるstable-diffusionを試してみます。 オンラインでも使えますが、ローカル環境に環境構築しても動きます。
構築
参考リンク1から関連ファイルをgit cloneすれば準備はOkです。 それぞれの環境で足りないライブラリはpipする必要があります。 各種エラー対処は、こちら2に先人がまとめてくれてますので参考に。
設定
GPUがあると描画は速いそうですが、持っていないのでGPU使わない設定が必要です。 webui-user.shを修正します。オプションを追記して、コメントアウトします。
| |
実行状況
実行すると、関連ファイルを引っ張ってきてwebui環境が待ち受けとなります。
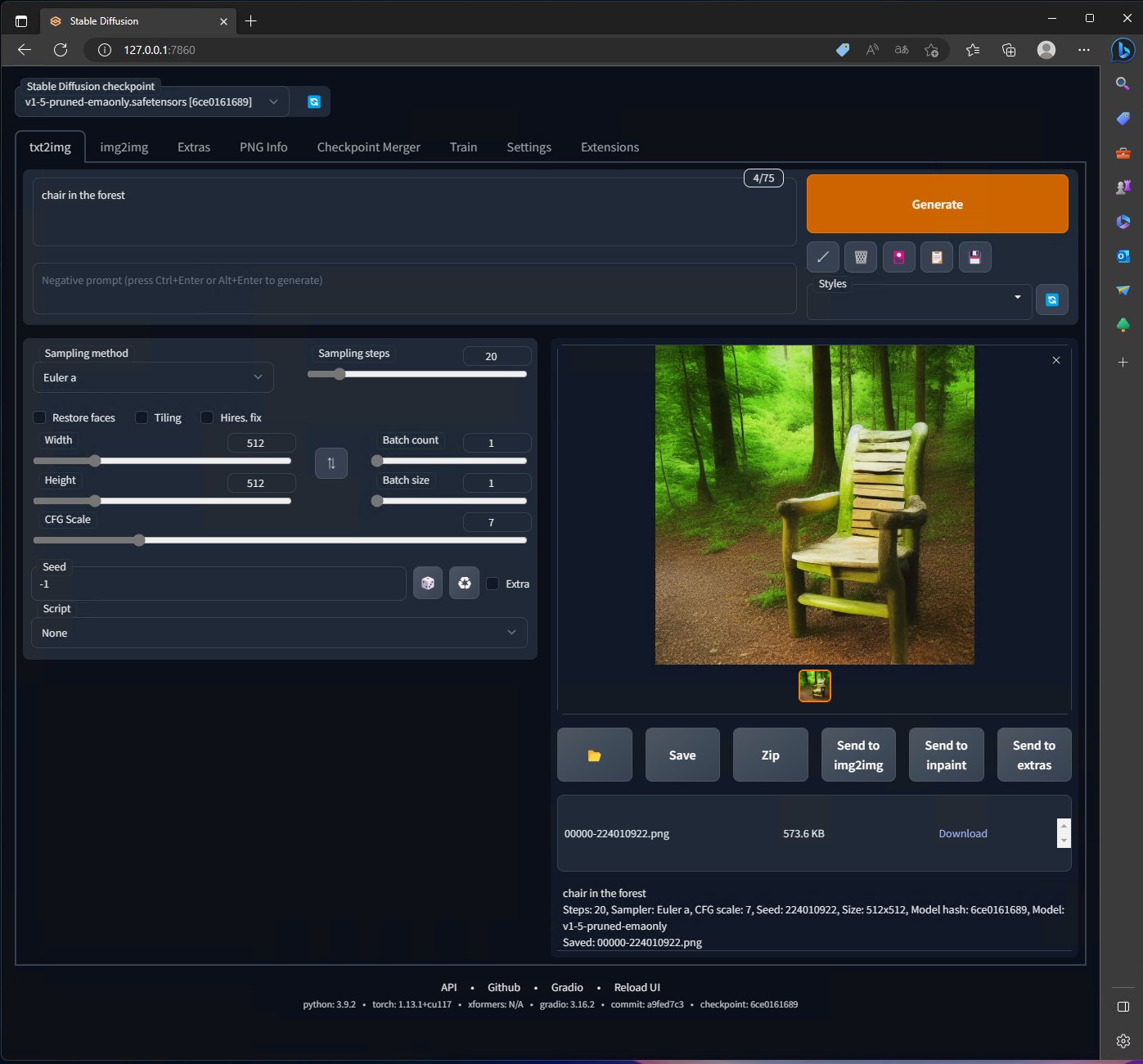
ブラウザーからhttp://127.0.0.1:7860にアクセスするとUI画面が出てきます。
| |
promptに「chair in the forest」と書いてgenerateした結果です。
動作環境は、
- プロセッサ Intel(R) Celeron(R) N5100 @ 1.10GHz 1.10 GHz
- 実装 RAM 16.0 GB (15.8 GB 使用可能)
のWin11+WSL2(debian)上で構築しました。no GPUなので1枚の画像構築するのに15分程度かかります。
まとめ
ローカル環境にstable-diffusionを構築してテキストから画像作成を試してみました。 テキストの書き方はいろいろとあるようです。no GPUだと1枚描くのに15分程かかったので、 書き方の探求まで至ってません。引き続きAI環境のお試し続けたいと思います。